Gaussian Naive Bayes
Introduction
The advantages of Naive Bayes include :
- They require a small amount of training data to estimate the necessary parameters.
- Naive Bayes learners and classifiers can be extremely fast compared to more sophisticated methods.
- The decoupling of the class conditional feature distributions means that each distribution can be independently estimated as a one dimensional distribution. This in turn helps to alleviate problems stemming from the curse of dimensionality.
The disadvantages of Naive Bayes include :
- Although naive Bayes is known as a decent classifier, it is known to be a bad estimator, so the probability outputs from predict_proba are not to be taken too seriously.
Here is an example with a test cancer diagnostic (more on Udacity) :
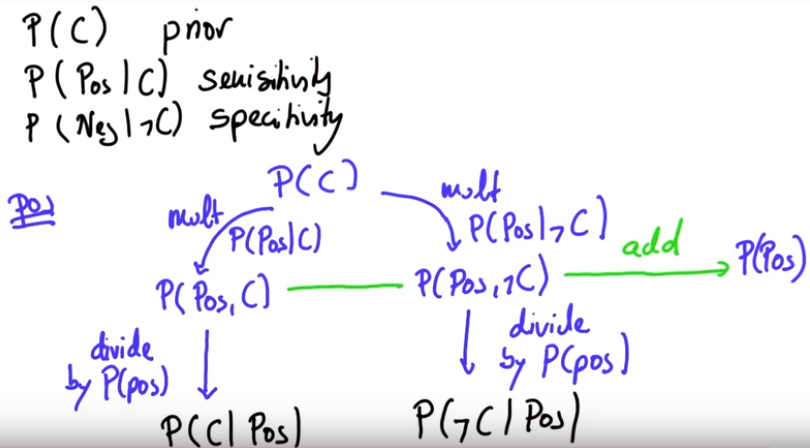
- P(C) : The prior condition here is the probability of having cancer.
- P(pos|C) : The sensitivity is the probability of the test being positive given that the person has cancer.
- P(neg|¬C) : The specificity if the probability of the test being negative given that the person does not have cancer.
$$P(C|pos) = {P(pos|C) P(C)\over P(pos)}$$
$$P(¬C|pos) = {P(pos|¬C) P(¬C)\over P(pos)}$$
Gaussian Naive Bayes for self-driving car
We want to train a car to decide weither or not it can drive faster or if it should slow down depending on the terrain. Two features will be taken into account in this project :
- Bumpiness: the more bumps on the road, the slower the car should go.
- Steepness: the steeper the road, the slower the car should go.
I will describe the procedure I went through step by step using Gaussian Naive Bayes as classifiers.
-
We first need to create a dataset of terrain with the features bumpiness and steepness along with a label "fast" or "slow". From this labeled dataset, we will be able to build a decision tree to help the car make it's decision : "Should I go slow or fast?"
### Modified from: Udacity - Intro to Machine Learning import random def makeTerrainData(n_points): random.seed(42) ### generate random data for both features 'grade' and 'bumpy' with an error grade = [random.random() for ii in range(0,n_points)] bumpy = [random.random() for ii in range(0,n_points)] error = [random.random() for ii in range(0,n_points)] ### data are labeled depending on their features and error. ### label "slow" if labels = 1.0 ### label "fast" if labels = 0.0 labels = [round(grade[ii]*bumpy[ii]+0.3+0.1*error[ii]) for ii in range(0,n_points)] ### adjust labels for extreme cases (>0.8) of bumpiness or steepness for ii in range(0, len(y)): if grade[ii]>0.8 or bumpy[ii]>0.8: labels[ii] = 1.0 ### split into train set (75% of data generated) and test sets (25% of data generated) features = [[gg, ss] for gg, ss in zip(grade, bumpy)] split = int(0.75*n_points) features_train = features[0:split] features_test = features[split:] labels_train = labels[0:split] labels_test = labels[split:] return features_train, labels_train, features_test, labels_testThe outputs are as follows for n_points = 10 :
features_train labels_train features_test labels_test grade bumpiness slow = 1.0 | fast = 0.0 grade bumpiness slow = 1.0 | fast = 0.0 0.64 0.22 1.0 0.09 0.59 0.0 0.03 0.51 0.0 0.42 0.81 1.0 0.28 0.03 0.0 0.03 0.01 0.0 0.22 0.20 0.0 0.74 0.64 1.0 0.68 0.54 1.0 0.89 0.22 1.0 For n_points = 1000, we get the following repartition of test points. We consider the feature 'bumpiness' on the x-axis and 'grade' on the y axis. Each feature in a gradient between 0 and 1. Each point previously generated has two coordinates bumpiness and grade. When we plot the test points (features_test) - representing 25% of our generated data - we can see the pattern separating the points labeled 'slow' and 'fast'.
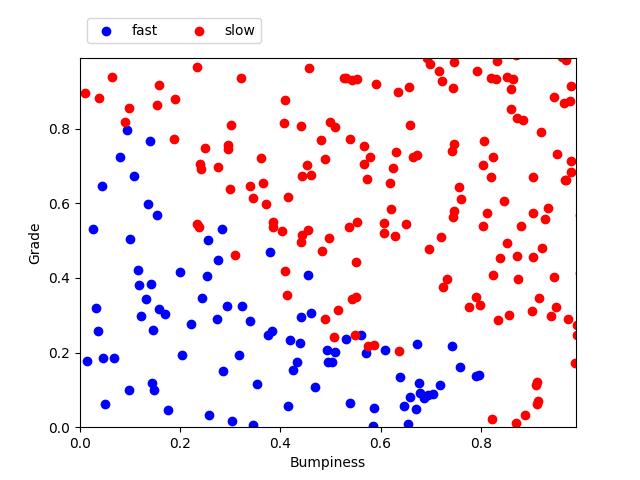
Testing set plotted with their labels
Testing set includes all features_test (grade, bumpiness) with their labels_test (slow or fast)
-
Now with our training set (features_train), we can train our classifier to predict a point's label depending on its features. We will use the class sklearn.naive_bayes.GaussianNB().
from prep_terrain_data import makeTerrainData from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score ### generate the dataset for 1000 points (see previous code) features_train, labels_train, features_test, labels_test = makeTerrainData(1000) ### create the classifier clf = GaussianNB() ### fit the training set clf.fit(features_train, labels_train) ### now let's make predictions on the test set prediction = clf.predict(features_test) ### measure of the accuracy score by comparing the prediction with the actual labels of the testing set accuracy = accuracy_score(labels_test, pred)Here I plotted the points from the testing set (features_test) with their labels (labels_test). On top is the prediction made by the classifier after fitting on the training set.
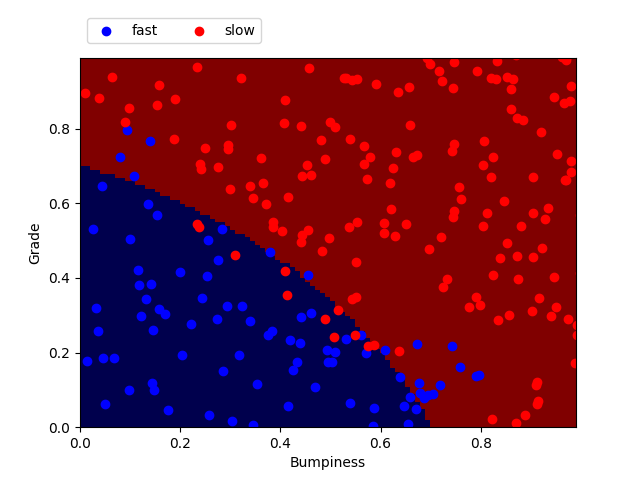
Decision tree with min_samples_split = 2
Classifier Training time (sec) Predict time (sec) Accuracy Gaussian Naive Bayes 0.003 0.001 0.884
Identifying emails authors with Gaussian Naive Bayes
Enron was one of the largest US companies in 2000. At the end of 2001, it had collapsed into bankruptcy due to widespread corporate fraud, known since as the Enron scandal. A vast amount of confidential information including thousands of emails and financial data was made public after Federal investigation.
In this project, I will apply Gaussian Naive Bayes to identify authors of emails in the Enron Corpus.
-
A big first part of the project is the preprocessing of emails which is described in more details here.
-
Once the emails are preprocessed and separated into a training and a testing set, the class sklearn.naive_bayes.GaussianNB() can be used.
from sklearn.naive_bayes import GaussianNB def nb_email(features_train, features_test, labels_train, labels_test): clf = GaussianNB() t0 = time() pred = clf.fit(features_train, labels_train) print ("naive bayes training time :", round(time() - t0, 3), "s") t0 = time() pred2 = clf.predict(features_test) print ("naive bayes predict time :", round(time() - t0, 3), "s") accuracy = accuracy_score(labels_test, pred2) print ("naive bayes accuracy :", accuracy) def main(): from_sara_file = "from_sara.txt" from_chris_file = "from_chris.txt" word_data, from_data = preprocess_email(from_sara_file, from_chris_file) features_train, features_test, labels_train, labels_test = vectorize(word_data, from_data) nb_email(features_train, features_test, labels_train, labels_test) if __name__ == '__main__': main()Classification algorithm Training time (sec) Predict time (sec) Accuracy Gaussian Naive Bayes 9.182 1.905 97.497